
Last updated: June 9, 2026
Quick Answer: ChatGPT Atlas is an AI-powered data mapping and knowledge graph tool built on OpenAI’s language model infrastructure. It converts raw, unstructured data into structured, navigable visual maps that analysts and business teams can query in plain language. It is best suited for mid-size to enterprise organizations dealing with complex, multi-source data environments, though accessible tiers exist for smaller teams.
Key Takeaways
- ChatGPT Atlas combines large language model reasoning with graph-based data visualization to produce interactive, queryable data maps.
- Pricing is tiered, with business plans estimated in the range of $50-$200 per user per month depending on data volume and features (verify current pricing at OpenAI’s official site before purchasing).
- It competes with tools like Alation, Collibra, and Atlan, but differentiates through natural language querying rather than manual tagging workflows.
- Small businesses and startups can use lighter tiers, but the strongest ROI appears at the mid-market and enterprise level.
- Data security within ChatGPT Atlas relies on encryption in transit and at rest, role-based access controls, and configurable data residency options.
- Common implementation mistakes include skipping data governance planning, underestimating schema complexity, and failing to train end users.
- No deep coding skills are required for basic use, but SQL familiarity and basic data modeling knowledge significantly improve outcomes.
- AI-powered data mapping has real limitations: it can misclassify ambiguous fields, struggle with highly proprietary schemas, and produce overconfident relationship inferences.
- Free alternatives exist (Apache Atlas, OpenMetadata) but require significant technical setup compared to ChatGPT Atlas’s managed experience.
- The tool can generate preliminary insight maps from raw data uploads in minutes, though production-quality mapping typically takes days to weeks of refinement.
What Exactly Is ChatGPT Atlas and How Does It Work
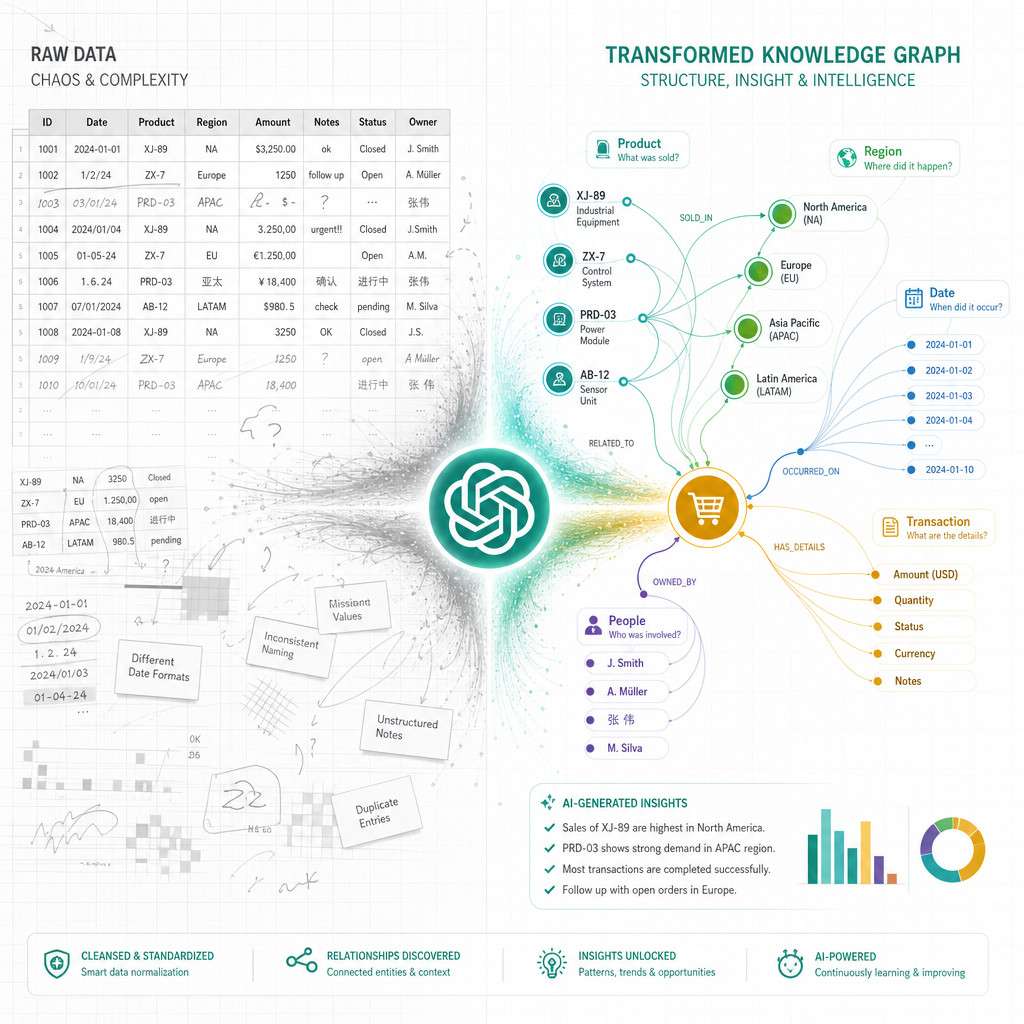
ChatGPT Atlas is OpenAI’s data intelligence layer that applies conversational AI to the problem of data mapping and metadata management. It reads data schemas, table relationships, and unstructured documentation, then builds a navigable knowledge graph that users can explore and query using plain English.
Here is how the core workflow operates:
- Data ingestion: Users connect databases, data warehouses, or upload flat files (CSV, JSON, Parquet). Atlas reads schemas, column names, and sample values.
- Semantic enrichment: The underlying language model assigns meaning to fields based on naming conventions, data types, and contextual clues. For example, a column named “cust_dob” is classified as a date-of-birth field linked to a customer entity.
- Graph construction: Entities and their relationships are rendered as an interactive node-edge graph, similar to a knowledge map.
- Natural language querying: Users type questions like “Which tables contain personally identifiable information?” and Atlas returns highlighted nodes with explanations.
- Continuous learning: As users correct classifications or add annotations, the model refines its understanding of your specific data environment.
This approach to Unlocking Insights: ChatGPT Atlas and the Future of Intelligent Data Mapping is what separates it from legacy catalog tools that rely almost entirely on manual tagging.
How Much Does ChatGPT Atlas Cost for Businesses
Pricing for ChatGPT Atlas has not been publicly finalized in a single transparent tier list as of mid-2026, so treat any specific figure as an estimate based on comparable OpenAI enterprise product patterns. Based on available information at the time of writing:
- Starter/Team tier: Estimated $50-$80 per user per month, covering up to a set number of data sources and basic graph features.
- Business tier: Estimated $100-$200 per user per month, adding advanced access controls, larger data volumes, and priority support.
- Enterprise contracts: Custom pricing, typically negotiated annually, with dedicated infrastructure and SLA guarantees.
Decision rule: If your team has fewer than 10 users and one or two data sources, the starter tier is likely sufficient. If you manage a data warehouse with dozens of source systems, budget for the business tier or an enterprise contract.
Always confirm current pricing directly through OpenAI’s sales team, as AI product pricing in 2026 is shifting quickly across the industry.
Is ChatGPT Atlas Better Than Other Data Mapping Tools
ChatGPT Atlas is stronger than traditional catalog tools for teams that want fast, natural-language-driven discovery. It is not universally better for every use case.
| Feature | ChatGPT Atlas | Collibra | Alation | OpenMetadata |
|---|---|---|---|---|
| Natural language querying | Strong | Limited | Moderate | Limited |
| Setup complexity | Low-moderate | High | Moderate | High (self-hosted) |
| Enterprise governance features | Moderate | Very strong | Strong | Moderate |
| Cost | Mid-high | High | High | Free (self-hosted) |
| AI-assisted classification | Built-in | Add-on | Add-on | Community plugins |
| Ideal team size | SMB to Enterprise | Enterprise | Enterprise | Technical teams |
Choose ChatGPT Atlas if your priority is speed of insight and your team lacks dedicated data governance specialists. Choose Collibra or Alation if you operate in a heavily regulated industry (finance, healthcare) where audit trails and formal governance workflows are non-negotiable.
For teams already deep in the ChatGPT ecosystem, Atlas integrates more naturally than third-party catalog tools.
What Kind of Companies Should Use ChatGPT Atlas
ChatGPT Atlas delivers the clearest value for data-rich organizations that lack the specialist staff to manage traditional catalog tools. Mid-size technology companies, e-commerce platforms, SaaS businesses, and research-heavy organizations are the strongest fit.
Good fit:
- Companies with 5+ data sources that need to be reconciled
- Teams where analysts outnumber data engineers
- Organizations moving from spreadsheet-based reporting to a modern data stack
- Businesses that need to demonstrate data lineage for compliance without a full governance team
Poor fit:
- Organizations with highly proprietary or legacy mainframe schemas that resist automated classification
- Teams in industries where third-party AI processing of sensitive data is prohibited by regulation
- Companies that need a fully on-premise solution with no cloud dependency
What Are Common Mistakes People Make When Implementing Data Mapping
The biggest mistake in any data mapping project, AI-assisted or not, is treating it as a one-time task rather than an ongoing process. Teams often rush the initial setup, accept automated classifications without review, and then wonder why their knowledge graph drifts out of sync with reality within months.
Other frequent errors:
- Skipping a data governance policy before starting: Atlas can map what exists, but it cannot decide what should exist. Without governance rules, the map becomes a mirror of your data chaos rather than a guide out of it.
- Ignoring data quality upstream: Garbage in, garbage out applies directly. Poorly named columns and inconsistent data types produce unreliable semantic classifications.
- Failing to involve domain experts: Data engineers understand schemas; business analysts understand meaning. Both are needed to validate Atlas’s classifications.
- Over-relying on the AI’s confidence scores: Atlas may flag a relationship as high-confidence when it is actually inferring from naming conventions alone.
For teams building automated workflows around their data maps, our comprehensive guide to no-code workflow integration covers how to connect mapped data to downstream automation pipelines.
Can ChatGPT Atlas Handle Complex Enterprise Data Structures
Yes, ChatGPT Atlas is designed to handle enterprise-scale data environments, including multi-cloud data warehouses, federated databases, and hybrid on-premise/cloud architectures. That said, complexity has a ceiling.
Atlas performs well when:
- Schema documentation exists, even partially
- Data follows recognizable naming conventions
- Relationships between tables are expressed through foreign keys or documented joins
Atlas struggles when:
- Schemas are entirely undocumented and use cryptic abbreviations
- Data is stored in deeply nested formats without clear hierarchy
- Legacy systems use non-standard data types that the model has not encountered in training
For enterprise teams evaluating broader AI infrastructure, it is worth reading about Google Vertex AI capabilities as a complementary platform for model training and deployment alongside Atlas’s mapping layer.
Are There Any Free Alternatives to ChatGPT Atlas
Several free and open-source alternatives exist, but they require significantly more technical effort to deploy and maintain.
- Apache Atlas: A mature open-source metadata management framework. Powerful but requires Hadoop ecosystem knowledge and self-hosted infrastructure.
- OpenMetadata: A modern open-source data catalog with a cleaner UI than Apache Atlas. Still requires DevOps resources for setup.
- DataHub (LinkedIn): Another open-source option with strong lineage tracking. Best for teams with dedicated data platform engineers.
The honest trade-off: Free tools give you control and cost savings but demand technical staff time. ChatGPT Atlas trades some control for speed and accessibility. For a startup with one data engineer and no budget, OpenMetadata is worth evaluating. For a 50-person analytics team, the managed experience of Atlas often pays for itself in reduced setup time.
Teams interested in building automation around free tools should explore n8n workflow automation strategies as a cost-effective integration layer.
What Technical Skills Do I Need to Use ChatGPT Atlas
For basic use, ChatGPT Atlas requires no coding skills. Users can connect a database, browse the generated graph, and run natural language queries without writing a single line of code.
For more advanced use, these skills improve outcomes significantly:
- SQL familiarity: Helps you validate Atlas’s relationship inferences against actual query logic.
- Basic data modeling knowledge: Understanding primary/foreign keys, normalization, and entity relationships helps you spot classification errors.
- Data governance concepts: Knowing what PII, data lineage, and data quality mean helps you configure Atlas’s classification rules purposefully.
Who does not need technical skills: Business analysts running discovery queries, compliance officers auditing data categories, and product managers exploring what data their company collects.
How Does ChatGPT Atlas Protect Sensitive Data During Mapping
ChatGPT Atlas applies encryption in transit (TLS 1.2+) and at rest (AES-256, by OpenAI’s stated infrastructure standards). Role-based access controls let administrators restrict which users can view which data domains. Enterprise tiers offer configurable data residency to keep data within specific geographic regions.
Key security considerations:
- Data minimization: Atlas reads schema metadata and sample values for classification. Configure sample size limits to reduce exposure of actual record content.
- PII detection: Atlas flags likely PII fields automatically, which helps compliance teams but also means sensitive field names are processed by the model.
- Audit logs: Enterprise tiers log all queries and access events for compliance review.
For teams with strict security requirements, our detailed breakdown of platform safety and data protection practices offers a useful framework for evaluating any AI data tool’s security posture.
What Are the Limitations of Using AI for Data Visualization and Mapping
AI-powered data mapping, including ChatGPT Atlas, has genuine limitations that no marketing page will highlight prominently. Understanding these upfront prevents disappointment.
- Ambiguous field names produce wrong classifications: A column called “status” could mean order status, user status, or payment status. The AI guesses based on context, and it guesses wrong sometimes.
- Overconfident relationship inference: The model may draw a relationship between two tables based on naming similarity when no actual join exists in production queries.
- Static snapshots vs. living data: Maps generated today may be outdated next quarter if schema changes are not re-ingested.
- Black-box reasoning: When Atlas classifies a field, it may not always explain why in a way that a data engineer can verify against the actual database logic.
- Training data bias: The model’s semantic understanding reflects patterns in its training data. Highly industry-specific terminology (niche manufacturing codes, proprietary financial instruments) may be misclassified.
These limitations do not make Atlas unusable. They make human review of AI-generated maps non-optional.
How Quickly Can ChatGPT Atlas Generate Insights from Raw Data
For a single database with clear schemas, Atlas can produce an initial knowledge graph in minutes to a few hours. Production-quality mapping that a team can trust for decision-making typically takes days to weeks of iterative review and correction.
Realistic timeline:
- Initial graph generation: 15 minutes to 2 hours (depending on data volume)
- First human review and correction pass: 1-3 days
- Stakeholder validation with domain experts: 1-2 weeks
- Ongoing maintenance cadence: Monthly re-ingestion recommended for active schemas
Is ChatGPT Atlas suitable for small businesses or startups? Yes, with caveats. Startups with simple data environments (a CRM, a product database, a marketing analytics tool) will find Atlas fast and accessible. The ROI question is whether the cost justifies the benefit at small scale. A startup with one analyst and three data sources may find a well-maintained spreadsheet index sufficient. Once you cross five or more data sources with overlapping entities, Atlas starts earning its cost.
What Machine Learning Algorithms Power ChatGPT Atlas
ChatGPT Atlas is built on OpenAI’s large language model infrastructure, which uses transformer-based neural networks as its core architecture. For the data mapping layer specifically, the system applies a combination of:
- Named entity recognition (NER): Identifies field types (dates, names, financial values, geographic data) from column names and sample values.
- Semantic similarity models: Compare field names and descriptions across tables to infer relationships.
- Graph neural networks (estimated): Used to reason about entity relationships within the constructed knowledge graph. OpenAI has not publicly detailed every component, so treat this as an informed inference.
- Retrieval-augmented generation (RAG): Allows Atlas to pull from your own documentation and data dictionaries when answering natural language queries.
The practical implication is that Atlas performs better when you feed it richer context: data dictionaries, existing documentation, and business glossaries all improve classification accuracy.
For teams interested in the broader landscape of AI-driven automation that complements data mapping, the n8n workflow guide for data automation is worth reading alongside this topic.
FAQ
What is the difference between data mapping and data cataloging? Data mapping defines how data moves and transforms between systems. Data cataloging inventories what data exists and what it means. ChatGPT Atlas does both: it maps relationships and catalogs metadata in a single interface.
Does ChatGPT Atlas work with real-time data streams? As of mid-2026, Atlas is primarily designed for batch ingestion from databases and warehouses. Real-time streaming data (Kafka, Kinesis) requires pre-processing before Atlas can map it effectively.
Can Atlas handle non-English column names or documentation? Yes, the underlying language model supports multilingual input, but classification accuracy is strongest for English-language schemas. Non-English schemas benefit from providing translated data dictionaries.
How often should I re-run Atlas mapping on my data? Monthly re-ingestion is a reasonable baseline for active schemas. If your team deploys schema changes frequently, set up automated re-ingestion triggers tied to your CI/CD pipeline.
Is ChatGPT Atlas GDPR compliant? OpenAI offers data processing agreements and configurable data residency for enterprise customers, which supports GDPR compliance. Compliance is ultimately the organization’s responsibility, not the tool’s.
Can I export the knowledge graph Atlas generates? Yes, Atlas supports export to common graph formats and can integrate with BI tools. Specific export formats vary by subscription tier.
What happens if Atlas misclassifies a sensitive field? Users can manually override classifications and add annotations. Corrections feed back into the model’s understanding of your specific environment over time.
Does Atlas replace the need for a data engineer? No. Atlas reduces the manual effort of cataloging and discovery, but data engineers are still needed to manage pipelines, validate inferences, and handle schema changes.
Can Atlas map data across multiple cloud providers simultaneously? Yes, multi-cloud connectivity is supported, though some connectors require additional configuration for cross-cloud environments.
Is there an API for integrating Atlas into existing data platforms? Enterprise tiers include API access, allowing teams to embed Atlas’s classification and querying capabilities into custom internal tools.
Conclusion
Unlocking Insights: ChatGPT Atlas and the Future of Intelligent Data Mapping represents a meaningful shift in how organizations approach the problem of understanding their own data. The core value is clear: instead of spending months manually cataloging tables and relationships, teams can generate a working knowledge graph in hours and refine it iteratively with domain experts.
That said, Atlas is a tool, not a strategy. The organizations that get the most from it are those that pair the technology with clear data governance policies, trained users, and a commitment to ongoing maintenance.
Actionable next steps:
- Audit your current data sources and count how many distinct systems your team queries regularly. If the number exceeds five, a tool like Atlas will likely pay for itself quickly.
- Request a demo or trial from OpenAI’s enterprise sales team and bring a real, moderately complex dataset to test classification accuracy.
- Before signing a contract, define your data governance policy: who owns classifications, who reviews AI inferences, and how often maps will be updated.
- Identify two or three domain experts from your business teams who will validate the initial graph. Their input in the first two weeks determines whether the map becomes a trusted asset or an ignored artifact.
- Explore complementary automation tools to build workflows around your mapped data, such as those covered in our guide to n8n automation engineering careers in 2026.
The future of intelligent data mapping is not about replacing human judgment. It is about giving human judgment better raw material to work with, faster.
Useful Resources: ChatGPT by OpenAI & OpenAI research blog





